ceph存储集群环境的搭建较为复杂,即使参照官方文档,也容易在实际搭建过程中遇到各种各样的问题。这里我们详细的介绍两种安装方法:
本文主要介绍在Ubuntu16.04上通过ceph-deploy工具来快速部署一套ceph集群。
1. PREFLIGHT
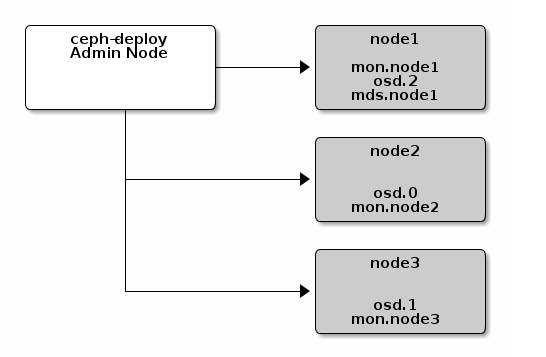
这里我们先给出我们将要创建的Ceph Storage Cluster的拓扑结构图。
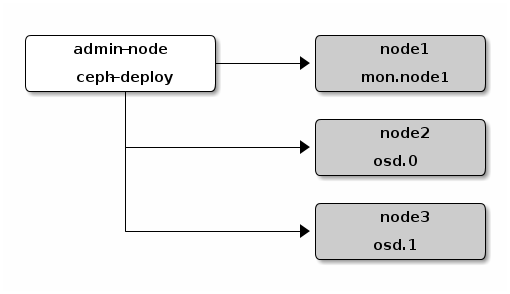
如上图所示,我们在admin节点上采用ceph-deploy来构建一个拥有3-node的Ceph存储集群。
在我们的构建过程中,我们采用4台Ubuntu16.04虚拟机:
主机IP |
部署组件 |
主机名 |
|---|---|---|
192.168.190.128 |
admin-node(ceph-deploy) |
ceph-admin |
192.168.190.129 |
node1(mon.node1) |
ceph-node1-mon |
192.168.190.130 |
node2(osd.0) |
ceph-node2-osd |
192.168.190.131 |
node3(osd.1) |
ceph-node3-osd |
修改上述每一个主机上的/etc/hosts文件,添加如下:
192.168.190.128 ceph-admin-3 192.168.190.129 ceph-node1-mon 192.168.190.130 ceph-node2-osd 192.168.190.131 ceph-node3-osd
修改每一个节点的主机名,将上面每一台虚拟机的主机名分别更改为ceph-admin,ceph-node1-mon,ceph-node2-osd,ceph-node3-osd。例如修改192.168.190.128主机的名字为ceph-admin:
# hostname ceph-admin
同时修改/etc/hostname文件,以使对主机名的更高永久生效。
1.1 CEPH DEPLOY SETUP
添加Ceph仓库到ceph-deploy admin node,然后开始安装ceph-deploy。
针对DEBIAN/UBUNTU执行如下步骤:
1) 添加release key
# wget -q -O- 'https://download.ceph.com/keys/release.asc' | sudo apt-key add -
2) 添加ceph包到仓库中,请用具体的Ceph稳定版本号替换{ceph-stable-release}(例如:hammer,jewel等)
# echo deb https://download.ceph.com/debian-{ceph-stable-release}/ $(lsb_release -sc) main | sudo tee /etc/apt/sources.list.d/ceph.list
这里我们选用jewel版本:
# echo deb https://download.ceph.com/debian-jewel/ $(lsb_release -sc) main | sudo tee /etc/apt/sources.list.d/ceph.list
NOTE: Ceph的一些发布版本可以在这里找到(http://docs.ceph.com/docs/master/releases/)
3) 更新源仓库并安装ceph-deploy
# sudo apt-get update && sudo apt-get install ceph-deploy
1.2 CEPH NODE SETUP
admin node(管理节点)必须要能够通过SSH password-less的访问Ceph节点。当ceph-deploy登录到ceph节点上的时候,该特殊的用户必须具有passwordless sudo特权。
1.2.1 INSTALL NTP
我们建议在Ceph所有的节点上(特别是Ceph Monitor节点)安装NTP来阻止由于时钟偏移所产生的问题。针对Debian/Ubuntu上执行如下命令:
# sudo apt-get install ntp
确保使能了NTP service,并且每一个Ceph节点都使用同样的NTP时间服务器。可以查看NTP对应的网站了解详细信息:http://www.ntp.org/
安装完成后通过如下命令查看NTP是否正常工作:

1.2.2 INSTALL SSH SERVER
针对所有的Ceph节点执行如下的步骤:
1) 安装一个SSH server到每一个Ceph节点上
# sudo apt-get install openssh-server
2) 确保SSH运行在所有Ceph节点上
# service --status-all | grep ssh
[ + ] ssh
1.2.3 CREATE A CEPH DEPLOY USER
ceph-deploy工具必须登录到Ceph节点上,并且必须具有passwordless sudo特权,因为需要登录到相应的节点上无密码的安装软件及配置文件。
最近版本的ceph-deploy支持–username选项 ,因此你可以指定任何用户使其具有password-less sudo权限(也包括root用户,但是并不推荐这样做)。为了使用ceph-deploy --username {username},你所指定的用户必须有通过SSH password-less的方式访问Ceph节点的权利,这样ceph-deploy就不会提示你输入密码。
我们推荐为ceph-deploy创建一个特定的用户来访问ceph集群节点。请不要使用“ceph”作为用户名。一个统一的用户名可以方便的对集群进行管理,但你应该避免用一些通常见到的用户名,这样可以防止黑客进行暴力的破解(例如:root、admin、{productname})。如下描述如何创建passwordless sudo用户的例子中请使用你自己定义的用户名来替换{username}。
Note: "ceph"用户名保留内部Ceph daemon使用
如下我们统一使用:
用户名:test1001
密码: 123456
1) 在每一个Ceph节点上创建一个新的用户
# ssh user@ceph-server
# sudo useradd -d /home/{username} -m {username}
# sudo passwd {username}
我们可以直接通过secureCRT登录到每一个节点上创建:
# sudo useradd -d /home/test1001 -m test1001
# sudo passwd test1001
2) 对于你为每一个Ceph添加的用户,确保其具有sudo权限
# echo "{username} ALL = (root) NOPASSWD:ALL" | sudo tee /etc/sudoers.d/{username}
# sudo chmod 0440 /etc/sudoers.d/{username}
针对我们的test1001用户:
# echo "test1001 ALL = (root) NOPASSWD:ALL" | sudo tee /etc/sudoers.d/test1001
# sudo chmod 0440 /etc/sudoers.d/test1001
1.2.4 ENABLE PASSWORD-LESS SSH
因为ceph-deploy并不会尝试输入密码,因此你必须在admin node(这里为192.168.190.128虚拟机)上产生SSH key,并将公钥分发到每一个Ceph节点上。
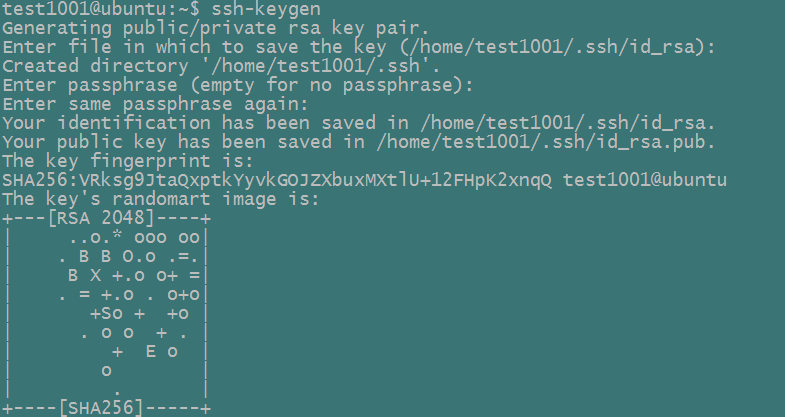
1) 产生SSH key,但是不要使用sudo或者root用户,并保持passphase为空
# ssh-keygen
Generating public/private key pair.
Enter file in which to save the key (/ceph-admin/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /ceph-admin/.ssh/id_rsa.
Your public key has been saved in /ceph-admin/.ssh/id_rsa.pub.
这里我们都统一切换为我们上面创建的test1001用户,然后再执行ssh-keygen:
2) 将key拷贝到每一个Ceph节点,请用你上面所创建的用户名替换{username}
ssh-copy-id {username}@node1
ssh-copy-id {username}@node2
ssh-copy-id {username}@node3
这里我们执行如下拷贝:
ssh-copy-id test1001@192.168.190.128
ssh-copy-id test1001@192.168.190.129
ssh-copy-id test1001@192.168.190.130
ssh-copy-id test1001@192.168.190.131
如下图所示:

我们尝试执行如下命令,看是否能够无密码登录到相应节点上:
# ssh test1001@192.168.190.128
# ssh test1001@192.168.190.129
# ssh test1001@192.168.190.130
# ssh test1001@192.168.190.131
3) 通过hostname方式访问对应的ceph节点
后续很多地方我们会通过hostname,而不是直接的IP地址的方式来访问ceph节点,因此这里我们修改所有节点的/etc/hosts文件来实现该功能。
# 192.168.190.128 ceph-admin
# 192.168.190.129 ceph-node1-mon
# 192.168.190.130 ceph-node2-osd
# 192.168.190.131 ceph-node3-osd
4)推荐修改ceph-deploy admin节点(这里为192.168.190.128)的~/.ssh/config文件,使ceph-deploy不需要在登录ceph集群节点的时候每一次都添加 --username {username}选项,对于ssh、scp等也可使用这一功能
这里切换到test1001用户,修改/home/test1001/.ssh/config文件:

添加完成之后,我们用ssh测试一下,不添加用户名也可以直接登录到对应的node节点:
注意:这里第一次使用ssh ceph-node1-mon的时候会要求你进行确认是否连接,后续则可以直接连接了。
1.2.5 ENABLE NETWORKING ON BOOTUP
Ubuntu16.04 暂时不需要做任何改变
1.2.6 ENSURE CONNECTIVITY
确保我们可以通过ping {hostname}的方式连通集群的各个节点,hostname地址解析在Ceph环境中很多地方会用到。注意,我们不应该将hostname解析成为一个127.0.0.1这样的本地回环地址。
这里我们通过上面的步骤修改/etc/hosts,已经完成了这一功能,在此只是再确认一下此功能是否有问题。
1.2.7 OPEN REQUIRED PORTS
Ceph monitors默认采用6789端口。Ceph OSDs默认采用6800~7300区间的端口进行通信。Ceph OSDs可以通过许多网络连接来与clients、monitors、其他OSDs进行通信。详细的网络配置可参考:http://docs.ceph.com/docs/master/rados/configuration/network-config-ref
在有一些环境中,默认的防火墙配置相当严格。你也许需要调整防火墙的设置以使客户端能够与Ceph daemons进行通信。
这里针对Ubuntu,我们暂时先禁止防火墙:
sudo ufw disable
2. STORAGE CLUSTER QUICK START
假如你暂时还未完成PREFLIGHT流程,请先参考上节完成。本章将会介绍通过在admin node上使用ceph-deploy来快速部署一套Ceph Storage Cluster。我们会创建拥有3个Ceph节点的集群来演示Ceph的一些功能
为了方便,我们再一次给出如上部署图。每一个节点对应的配置及IP地址请参看上节。
作为一个例子,我们首先会创建一个拥有1个Ceph Monitor,2个 Ceph OSD Daemons的集群。一旦该集群达到active + clean状态,可以通过再增加1个Ceph OSD Daemon,1个Metadata Server,2个Ceph Monitors来对集群进行扩展。最好在admin node上创建一个来存放ceph-deploy在部署集群时所产生的配置文件及keys文件。
# mkdir ceph-cluster
# cd ceph-cluster
如上,我们在admin node上,通过test1001账户在其home目录创建ceph-cluster文件夹(/home/test1001/ceph-cluster)。
ceph-deploy工具将会输出一些文件到当前目录,因此请确保当你执行ceph-deploy时在ceph-cluster目录下。
注意: 假如你以其他的用户身份登录的话,请不要用sudo或root身份执行ceph-deploy,因为它将不能处理远程主机所需要的sudo命令。
2.1 CREATE A CLUSTER
在任何你遇到了难以解决的问题,并且需要完全重新来过的话,可以执行如下的命令来彻底清除ceph包,并且删除对应的数据及配置。
# ceph-deploy purge {ceph-node} [{ceph-node}]
# ceph-deploy purgedata {ceph-node} [{ceph-node}]
# ceph-deploy forgetkeys
假如你执行了purge,你必须再一次重新安装Ceph。
在admin node主机的ceph-cluster目录,使用ceph-deploy按如下步骤进行操作:
1) 创建集群
# ceph-deploy new {initial-monitor-node(s)}
请指定node(s)为hostname,fqdn或者hostname:fqdn,例如:
# ceph-deploy new ceph-node1-mon
注意:此处执行需要test1001具有password-less sudo权限
执行完成之后,通过ls及cat命令查看当前目录。你会看到有一个Ceph配置文件,一个monitor secret keyring,及一个日志文件。请用ceph-deploy new –h来获得更多帮助信息。

2) 在Ceph配置文件中将副本数的默认值从3改为2,使Ceph集群在只有两个Ceph OSDs的情况下也能达到active + clean状态。添加如下行到[global]段下:
osd pool default size = 2
3) 假如ceph部署主机拥有超过一个网络接口,在ceph配置文件的[global]段下添加public network设置。请参看Networking Configuration Reference来获取更详细信息
public network = {ip-address}/{netmask}
这里我们设置如下:
public network = 192.168.190.0/24
4) 安装Ceph
ceph-deploy install {ceph-node}[{ceph-node} ...]
这里我们安装如下:
ceph-deploy install ceph-admin ceph-node1-mon ceph-node2-osd ceph-node3-osd
ceph-deploy工具将会在每一个节点上安装ceph。注意:假如你使用ceph-deploy purge,你必须重新执行本步骤来安装Ceph。
注意:
如果在安装过程中出现initctl: Unable to connect to Upstart: Failed to connect to socket /com/ubuntu/upstart: Connection refused错误,可以执行如下命令:
# dpkg-divert –local --rename --add /sbin/initctl
# ln -s /bin/true /sbin/initctl
5) 添加initial monitor(s)并且收集keys
# ceph-deploy mon create-initial
一旦你完成了该进程,你的本地目录将会有如下的一些keyrings:
- ${cluster-name}.client.admin.keyring
- ${cluster-name}.bootstrap-osd.keyring
- ${cluster-name}.bootstrap-mds.keyring
- ${cluster-name}.bootstrap-rgw.keyring
这里我们生成的keys如下:
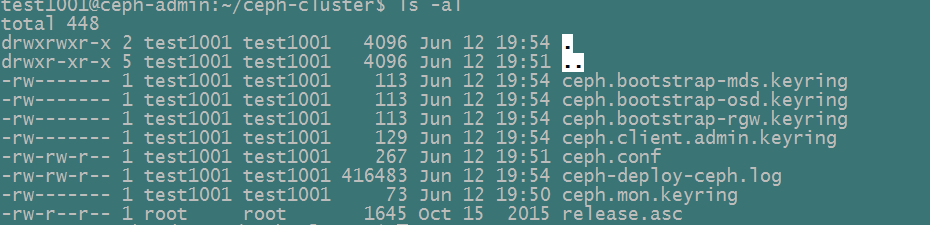
Note1: bootstrap-rgw.keyring只会在Hammer或者更新版本的Ceph集群安装时才会创建
Note2:假如执行上面的create-initial命令时出现类似“Unable to find /etc/ceph/ceph.client.admin.keyring”的错误时,在ceph.conf中列出的monitor node的IP地址是一个public IP,而不是private IP。
执行完上面的流程之后,我们已经快速的完成了一个简单Ceph集群的安装。如下我们再介绍一下与安装、使用相关的一些其他方面的内容:
1) 添加两个OSDs
1.1) 针对快速安装,我们将每一个Ceph OSD Daemon设置为使用一个目录而不是整个硬盘。关于OSDs及journals如何使用单独的disks/partitions,请参看ceph-deploy osd:(http://docs.ceph.com/docs/master/rados/deployment/ceph-deploy-osd)。登录对应的Ceph节点(这里为ceph-node2-osd和ceph-node3-osd),然后为Ceph OSD Daemon创建一个目录:
ssh ceph-node2-osd
sudo mkdir /var/local/node2_osd
exit
ssh ceph-node3-osd
sudo mkdir /var/local/node3_osd
exit
注意:在OSD存储分区的文件系统不是xfs时,有时候会在后面我们启动的时候出现这样的错误“ERROR: osd init failed: (36) File name too long”,此时需要设置一些OSD变量(ceph.conf的global段):
osd max object name len = 256
osd max object namespace len = 64
1.2) 登录ceph admin节点,为远程主机(这里为ceph-node2-osd、ceph-node3-osd节点)Ceph OSD Daemon准备存储数据的磁盘
ceph-deploy osd prepare {ceph-node}:/path/to/directory
这里我们配置如下:
ceph-deploy osd prepare ceph-node2-osd:/var/local/node2_osd ceph-node3-osd:/var/local/node3_osd
1.3) 激活OSDs
ceph-deploy osd activate {ceph-node}:/path/to/directory
这里我们配置如下:
ceph-deploy osd activate ceph-node2-osd:/var/local/node2_osd ceph-node3-osd:/var/local/node3_osd
这里我们可能会遇到“Permission denied”的问题,此时需要更改对应目录的权限(更改为Ceph集群内部保留的ceph用户,及ceph组):
sudo chown ceph:ceph /var/local/node2_osd/ -R
sudo chown ceph:ceph /var/local/node3_osd/ -R
1.4) 使用ceph-deploy命令来拷贝配置文件、admin key到admin node和 Ceph Nodes上面,这样你就可以在使用ceph CLI(命令行)执行命令时,不必每一次都指定monitor address和ceph.client.admin.keyring
ceph-deploy admin {admin-node} {ceph-node}
这里我们配置如下:
ceph-deploy admin ceph-admin ceph-node1-mon ceph-node2-osd ceph-node3-osd
执行本命令会将ceph.client.admin.keyring及ceph.conf推送到对应节点的/etc/ceph目录下
1.5) 确保具有读取ceph.client.admin.keyring的权限
在所有节点上执行如下语句:
sudo chmod +r /etc/ceph/ceph.client.admin.keyring
3) 检查集群是否工作正常
ceph health
这里我们检查集群状态为:
2.2 EXPANDING YOUR CLUSTER
一旦你已经建立起来一个基本的集群并运行起来之后,后面你就可以对该集群进行扩展。这里我们添加一个Ceph OSD Daemon和一个Ceph Metadata Server到node1上,然后再添加一个Ceph Monitor到node2和node3上以达到指定数量的Ceph Monitors。
1)ADDING AN OSD
我们通过上面的安装步骤已经建立起了3个节点的ceph集群,这里我们添加OSD到monitor node(ceph-node1-mon)上
1.1)从ceph-admin上登录ceph-node1-mon上
ssh ceph-node1-mon
sudo mkdir /var/local/node1_osd
exit
这里也要设置要相应的权限:
sudo chown ceph:ceph /var/local/node1_osd/ -R
1.2)从ceph-deploy节点(ceph-admin)上准备好OSD
ceph-deploy osd prepare {ceph-node}:/path/to/directory
这里我们配置为如下:
ceph-deploy osd prepare ceph-node1-mon:/var/local/node1_osd
1.3) activate the OSDs
ceph-deploy osd activate {ceph-node}:/path/to/directory
这里我们配置为如下:
ceph-deploy osd activate ceph-node1-mon:/var/local/node1_osd
1.4) 一旦已经添加了新的OSD,Ceph就会通过迁移placement groups到你新添加的OSD上面以达到集群的均衡,你可以通过ceph命令行观察到这个迁移
ceph -w
通过上面的命令,你可以看到placement group的状态从active + clean 变为active with some degraded objects,最后当迁移完成之后又会变成active + clean状态。
2) ADD AN METADATA SERVER
为了使用CephFS,你需要至少一个metadata server,执行如下的命令来创建一个metadata server:
ceph-deploy mds create {ceph-node}
这里我们在node1(ceph-node1-mon)上部署metadata server:
ceph-deploy mds create ceph-node1-mon
执行完成之后,我们可以到ceph-node1-mon主机上通过ps看到mds进程已经运行起来了。
NOTE: 当前在实际的Ceph产品中只会运行一个metadata server。你可以使用多个,但是当前没有商业上对多metadata server的ceph集群的支持
3) ADD AN RGW INSTANCE
为了使用Ceph的Ceph Object Gateway(ceph对象网关)组件,你必须部署一个RGW实例。执行如下的命令来创建一个新的RGW实例:
ceph-deploy rgw create {gateway-node}
这里配置为:
ceph-deploy rgw create ceph-node1-mon
NOTE: RGW功能是从Hammer开始才有的一项功能,ceph-deploy从v1.5.23开始才支持rgw命令
这里可以通过如下命令来进行访问:

默认情况下,RGW会监听7480端口。可以通过修改运行RGW节点上的ceph.conf文件来更改端口:
[client]
rgw frontends = civetweb port=80
使用IPv6地址的话,可以采用如下方式:
[client]
rgw frontends = civetweb port=[::]:80
4) ADDING MONITORS
一个ceph存储集群需要至少运行一个Ceph monitor。为了达到高可用性,Ceph Storage Clusters通常会运行多个Ceph Monitors,这样当一个Ceph monitor失效的情况下并不会导致整个存储集群不能正常工作。Ceph使用Paxos算法,其需要获得所有monitor的多数工作正常。
如下,我们添加两个Ceph monitors到集群中:
ceph-deploy mon add {ceph-node}
这里我们配置为:
ceph-deploy mon add ceph-node2-osd
ceph-deploy mon add ceph-node3-osd
一旦你已经添加了新的ceph monitors,ceph就会同步这些monitors然后形成一个quorum,你可以通过如下的命令来获得quorum的状态:
ceph quorum_status --format json-pretty
Tips:当你运行多个ceph monitors的时候,你需要在每一台monitor主机上安装和配置NTP来确保这些monitors是NTP peers
2.3 STORING/RETRIEVING OBJECT DATA
为了在Ceph Storage Cluster中存储对象数据,一个Ceph client必须:
- Set an object name
- Specify a pool
Ceph Client获得最新的cluster map,然后通过CRUSH算法计算出如何将一个对象映射到placement group上,然后再计算出如何指定一个placement group到一个Ceph OSD Daemon上。为了找到该对象的位置,你只需要给出对象名及pool名即可。例如:
ceph osd map {poolname} {object-name}
下面给出一个存储/获取对象数据的例子(Locate an Object):
1) 首先创建一个对象。指定一个对象的名字,一个包含对象数据的文件路径和一个pool名字
echo {Test-data} > testfile.txt
rados mkpool data
rados put {object-name} {file-path} --pool=data
rados put test-object-1 testfile.txt --pool=data
2) 确定Ceph Storage Cluster已经存储了该对象,执行如下命令
rados -p data ls
执行结果如下:

3) 获得该对象的存储位置
ceph osd map {pool-name} {object-name}
ceph osd map data test-object-1
执行结果如下:

4) 获取一个对象
从data这个pool中获取test-object-1对象,结果输出到abcd.txt中:
rados –p data get test-object-1 abcd.txt
5) 移除一个对象
rados rm test-object-1 --pool=data
随着集群的变化,对象的存储位置也有可能会动态的发生变化。Ceph的动态均衡特性使得这些对象可以自动的进行迁移。
3. BLOCK DEVICE QUICK START
在使用block device之前,请确保你已经通过上面的STORAGE CLUSTER QUICK STAR建立起了一套active + clean状态的Ceph Storage Cluster。
NOTE:Ceph Block Device也被称为RBD或RADOS Block Device.
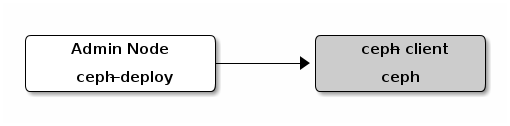
你可以使用一台虚拟机设备来作为ceph-client节点,但是不要在与你的Ceph Storage Cluster集群节点的物理机上执行如下操作(除非你使用的是虚拟机)。
注意:实际实验时,由于条件的限制我们会将ceph-admin与ceph-client运行在同一台虚拟机上,但是如下讲解时,还是会按两个不同的主机来进行讲解。
3.1 INSTALL CEPH
1)检查对应的Linux Kernel版本是否合适
lsb_release -a uname -r
2) 在admin node上,使用ceph-deploy来将ceph安装到ceph-client节点上
ceph-deploy install ceph-client
3) 在admin node上,使用ceph-deploy命令来拷贝Ceph配置文件和ceph.client.admin.keyring文件到ceph-client上
ceph-deploy admin ceph-client
ceph-deploy工具会拷贝keyring文件到/etc/ceph目录下。请确保该keyring文件具有合适的读权限(例如:sudo chmod +r /etc/ceph/ceph.client.admin.keyring)
3.2 CONFIGURE A BLOCK DEVICE
1) 在ceph-client node上,创建一个block device image
rbd create foo --size 4096 [-m {mon-IP}] [-k /path/to/ceph.client.admin.keyring]
2) 在ceph-client节点,将创建的image映射到block device上
sudo rbd map foo --name client.admin [-m {mon-IP}] [-k /path/to/ceph.client.admin.keyring]
这里我们会得到如下错误:

| 执行命令”dmesg | tai”查看: |
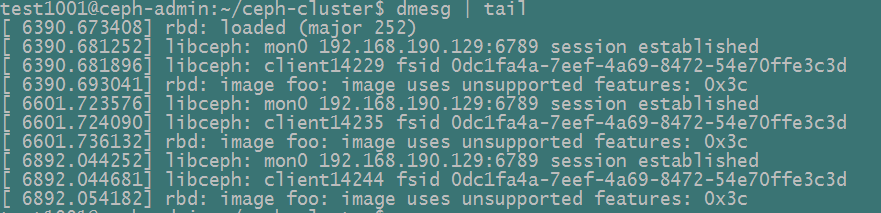
问题的原因在于在Ceph高版本进行map image时,默认Ceph在创建image(上面的foo)时会增加血多features,这些features需要内核支持,在这里Ubuntu16.04内核支持有限,所以需要手动关掉一些features。
我们首先使用rbd info foo来查看foo当前所支持的featrues:

上面我们创建的foo映像有很多特征,我们这里可以手动关掉一些特征,然后重新map;如果要想一劳永逸,可以在ceph.conf中加入rbd_default_featrues = 1来设置默认的features(数值仅是layering对应的bit码所对应的整数值)。
这里关闭不支持的特性:
rbd feature disable foo exclusive-lock, object-map, fast-diff, deep-flatten
然后重新映射:
sudo rbd map foo --name client.admin
这里映射成功:

4) 在ceph-client节点上使用该block device创建一个文件系统
sudo mkfs.ext4 -m0 /dev/rbd/rbd/foo This may take a few moments.
5) 将创建的文件系统挂载到ceph-client节点上
sudo mkdir /mnt/ceph-block-device sudo mount /dev/rbd/rbd/foo /mnt/ceph-block-device cd /mnt/ceph-block-device
6) 配置该block device在系统启动的时候自动映射及挂载(在关机的时候自动unmounted/unmapped)
4. CEPH FS QUICK START
在使用block device之前,请确保你已经通过上面的STORAGE CLUSTER QUICK START建立起了一套Ceph Storage Cluster。请在admin host上执行本quick start。
4.1 PREREQUISITES
1)确保你有一个合适的Linux内核版本
lsb_release -a uname -r
2)在admin节点上,使用ceph-deploy安装ceph到ceph-client节点上
ceph-deploy install ceph-client
3)确保Ceph Storage Cluster处于active + clean的运行状态,同时确保至少有一个Ceph Metadata Server正在运行
ceph -s [-m {monitor-ip-address}] [-k {path/to/ceph.client.admin.keyring}]
4.2 CREATE A FILESYSTEM
我们已经在前面“STORAGE CLUSTER QUICK START”中创建了一个MDS,但是在你创建pools和文件系统之前它是处于inactive状态。请参看: Create a Ceph filesystem(http://docs.ceph.com/docs/master/cephfs/createfs/)
ceph osd pool create cephfs_data <pg_num> ceph osd pool create cephfs_metadata <pg_num> ceph fs new <fs_name> cephfs_metadata cephfs_data
这里我们配置如下:
ceph osd pool create cephfs_data 32 ceph osd pool create cephfs_metadata 32 ceph fs new testfs cephfs_metadata cephfs_data

这里简单介绍一下PG的概念:
当Ceph集群接收到存储请求时,Ceph会将其分散到各个PG中,PG是一组对象的逻辑集合;根据Ceph存储池的复制级别,每个PG的数量都会被复制并分发到集群的多个OSD上;一般来说增加PG数量能降低OSD负载,一般每个OSD大约分配50~100PG,关于PG数量一般遵循以下公式:
- 集群PG总数 = (OSD 总数 * 100)/数据最大副本数
- 单个存储池PG数 = (OSD 总数 * 100)/数据最大副本数/存储池数
注意,PG最终结果应当为最接近以上计算公式的2的N次幂(向上取值);如我的虚拟机环境每个存储池PG数 = 3(OSD) * 100/3(副本)/5(大约5个存储池) = 20,向上取2的N次幂为32。
4.2 CREATE A SECTET FILE
Ceph Storage Cluster默认会开启身份认证机制。你需要创建一个包含secret key的文件(注意:并不是keyring本身)。针对一个特定的用户建立secret key的操作步骤如下:
1) 在一个keyring文件中标识一个用户,例如:
cat ceph.client.admin.keyring
2) 拷贝需要使用挂载Ceph文件系统的用户的key,类似于如下:
[client.admin] key = AQCj2YpRiAe6CxAA7/ETt7Hcl9IyxyYciVs47w==
3) 打开一个文本编辑器
4) 将key复制到该空文件中。类似于如下:
AQCj2YpRiAe6CxAA7/ETt7Hcl9IyxyYciVs47w==
5) Save the file with the user name as an attribute (e.g., admin.secret)
6)确保该用户具有适当的权限访问该secret文件,对于其他用户则不可见
4.3 KERNEL DRIVER
内核驱动挂载Ceph FS
sudo mkdir /mnt/mycephfs
sudo mount -t ceph {ip-address-of-monitor}:6789:/ /mnt/mycephfs
Ceph Storage Cluster默认会使用身份验证机制,在挂载的时候需要指定name及secretfile。例如:
sudo mount -t ceph 192.168.0.1:6789:/ /mnt/mycephfs -o name=admin,secretfile=admin.secret
注意:有些版本的Linux内核mount并不支持secretfile选项,比如Ubuntu16.04似乎只支持secret选项:
sudo mount -t ceph 192.168.0.1:6789:/ /mnt/mycephfs -o name=admin,secret= AQDNUz9ZZiI6GBAAolxzpG2mLypQ51SA+zyrog==
NOTE:请在admin节点上挂载Ceph FS文件系统,不要在server节点上
4.4 FILESYSTEM IN USER SPACE(FUSE)
1)安装ceph-fuse
sudo apt-get install ceph-fuse
2)在用户空间挂载Ceph FS(FUSE)
sudo mkdir ~/mycephfs
sudo ceph-fuse -m {ip-address-of-monitor}:6789 ~/mycephfs
默认情况下Ceph Storage Cluster会使用身份认证机制,假如对应的keyring不在默认位置的话(/etc/ceph),请显示指定:
sudo ceph-fuse -k ./ceph.client.admin.keyring -m 192.168.0.1:6789 ~/mycephfs
4.5 UMOUNT
sudo umount /mnt/mycephfs sudo umount ~/mycephfs
5 CEPH OBJECT GATEWAY QUICK START
从版本v0.80开始,Ceph Storage大大的简化了Ceph Object Gateway的安装与配置。Gateway Daemon内嵌了Civetweb,因此你并不需要再安装一个web服务器或者配置FastCGI。另外,ceph-deploy也可以安装gateway包,产生key,配置一个data目录及创建一个gateway实例。
Tip:Civetweb默认使用7480端口。你必须允许打开该端口,又或者在ceph.conf配置文件中选择另一个端口(例如80端口)
建立一个Ceph Object Gateway,请参照如下的步骤:
5.1 INSTALLING CEPH OBJECT GATEWAY
1)在client-node上执行预安装步骤。假如需要使用Civetweb的默认端口7480的话,你必须使用firewall-cmd 或 iptables打开该端口。
2)从admin node上的工作目录,在client-node上安装Ceph Object Gateway
ceph-deploy install --rgw <client-node> [<client-node> ...]
这里,我们在“STORAGE CLUSTER QUICK START”中已经全部安装了ceph相关的一些工具,也包括rgw,因此这里可以不用再进行安装。
5.2 CREATING THE CEPH OBJECT GATEWAY INSTANCE
从admin节点的工作目录,在client-node节点上创建一个Ceph Object Gateway,例如:
ceph-deploy rgw create <client-node>
一旦该gateway运行之后,你可以通过7480端口访问它(http://client-node:7480)
5.3 CONFIGURING THE CEPH OBJECT GATEWAY INSTANCE
1) 要改变默认的端口,请修改ceph配置文件。添加一个[client.rgw.
[client.rgw.client-node] rgw_frontends = "civetweb port=80"
NOTE: 请确保port=<port-number>之间是没有空格的
2) 为了使端口设置生效,需要重启Ceph Object Gateway
sudo service radosgw restart id=rgw.<short-hostname>
3:检查防火墙,看选中的80端口是否已经打开。假如没有打开,添加该端口并重新加载防火墙配置
sudo firewall-cmd --list-all sudo firewall-cmd --zone=public --add-port 80/tcp --permanent sudo firewall-cmd --reload
4:通过http访问
http://${client-node}:${port}