概览
如下我们是在无外网环境的centos7.1上手动安装ceph集群。
cat /etc/redhat-release Centos Linux release 7.1.1503 (Core)
我们这里采用了4台虚拟机:
主机IP |
部署组件 |
主机名 |
|---|---|---|
172.20.30.196 |
admin-node |
ceph001-admin |
10.133,134,211 |
node1 |
ceph001-node1 |
10.133.134.212 |
node2 |
ceph001-node2 |
10.133.134.213 |
node3 |
ceph001-node3 |
1) 在上述所有节点上修改/etc/hosts中添加如下内容:
# For Ceph Cluster 172.20.30.196 ceph001-admin 10.133.134.211 ceph001-node1 10.133.134.212 ceph001-node2 10.133.134.213 ceph001-node3
2) 修改主机名
在上述所有节点上分别修改/etc/sysconfig/network文件,指定其主机名分别为ceph001-admin、ceph001-node1、ceph001-node2、ceph001-node3。例如:

上述修改需要在系统下次重启时才生效。
此外,我们需要分别在每一个节点上执行hostname命令来立即更改主机名称。例如:

3) 通过主机名测试各节点之间是否联通
例如:

4) 检查当前CentOS内核版本是否支持rbd,并装载rbd模块
modinfo rbd modprobe rbd #装载rbd模块 lsmod | grep rbd #查看模块是否已经装载
5) 安装ntp,并配置ceph集群节点之间的时间同步
在各节点执行如下命令:
rpm –qa | grep ntp #查看当前是否已经安装ntp ps –ef | grep ntp # 查看ntp服务器是否启动 ntpstat #查看当前的同步状态
在/etc/ntp.conf配置文件中配置时间同步服务器地址
参看:http://www.centoscn.com/CentosServer/test/2016/0129/6709.html
6)关闭iptables
这里我们直接关闭iptables
systemctl stop firewalld.service ##停止iptables服务 systemctl disable firewalld.service ##关闭iptables开机运行
7) TTY
在CentOS及RHEL上,当你尝试执行ceph-deploy时,你也许会收到一个错误。假如requiretty在你的Ceph节点上默认被设置了的话,可以执行sudo visudo然后定位到Defaults requiretty的设置部分,将其改变为Defaults:ceph !requiretty或者直接将其注释掉
NOTE:假如直接修改/etc/sudoers,确保使用sudo visudo,而不要用其他的文本编辑器
8) SELINUX
在CentOS及RHEL上,SELINUX默认会设置Enforcing。为了顺利的进行安装,我们建议设置SELINUX为Permissive或者完全禁止它。设置SELINUX值为Permissive,执行如下的命令:
sudo setenforce 0
为了永久的配置SELinux(假如SELinux会影响到Ceph集群的安装、运行的话),请修改配置文件/etc/selinux/config.
sudo sed -i 's/SELINUX=enforcing/SELINUX=disabled/' /etc/selinux/config ##关闭SELinux开机启动
1. Get Software
1.1 ADD KEYS
添加key到你的系统受信任keys列表来避免一些安全上的警告信息,对于major releases(例如hammer,jewel)请使用release.asc。
我们先从https://download.ceph.com/keys/release.asc 下载对应的release.asc文件,上传到集群的每一个节点上,执行如下命令:
sudo rpm --import './release.asc'
1.2 DOWNLOAD PACKAGES
假如你是需要在无网络访问的防火墙后安装ceph集群,在安装之前你必须要获得相应的安装包。注意,你的连接外网的下载ceph安装包的机器环境与你实际安装ceph集群的环境最好一致,否则可能出现安装包版本不一致的情况而出现错误。。
RPM PACKAGES
先新建三个文件夹dependencies、ceph、ceph-deploy分别存放下面下载的安装包。
1) Ceph需要一些额外的第三方库。添加EPEL repository,执行如下命令:
sudo yum install -y https://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm
Ceph需要如下一些依赖包:
- snappy
- leveldb
- gdisk
- python-argparse
- gperftools-libs
现在一台可以连接外网的主机上下载这些依赖包,存放在dependencies文件夹:
sudo yumdownloader snappy sudo yumdownloader leveldb sudo yumdownloader gdisk sudo yumdownloader python-argparse sudo yumdownloader gperftools-libs
2) 安装yum-plugin-priorities
sudo yum install yum-plugin-priorities
修改/etc/yum/pluginconf.d/priorities.conf文件:
[main] enabled = 1
3) 通过如下的命令下载适当版本的ceph安装包
su -c 'rpm -Uvh https://download.ceph.com/rpm-{release-name}/{distro}/noarch/ceph-{version}.{distro}.noarch.rpm'
也可以直接到官方对应的网站去下载:
https://download.ceph.com/
这里我们在CentOS7.1上配置如下:
su -c 'rpm -Uvh https://download.ceph.com/rpm-jewel/el7/noarch/ceph-release-1-0.el7.noarch.rpm'
修改/etc/yum.repos.d/ceph.repo文件,添加priority项:
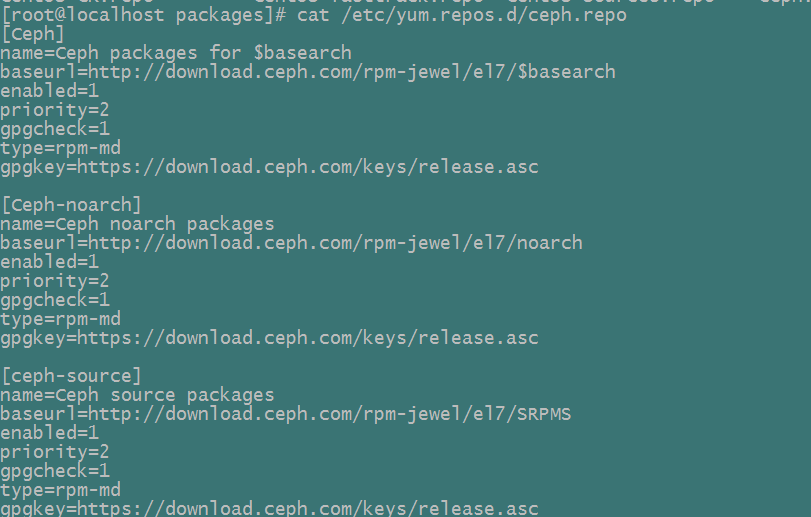
下载ceph安装包:
yum clean packages #先清除本地可能缓存的一些包 yum clean yum repolist yum makecache sudo yum install --downloadonly --downloaddir=/ceph-cluster/packages/ceph ceph ceph-radosgw
NOTE1:这里我们目前就下载ceph,ceph-radosgw两个包,其依赖的一些包会自动下载下来。如果在实际安装中,仍缺少一些依赖包,我们可以通过yum search ${package-name} 查找到该包,然后再下载下来.
NOTE2: 上面这是下载最新版本的ceph安装包,如果下载其他版本,请携带上版本号
4)下载ceph-deploy安装包
sudo yum install --downloadonly --downloaddir=/ceph-cluster/packages/ceph-deploy ceph-deploy
4) 将上述的依赖包分别打包压缩称dependencies.tar.gz、ceph.tar.gz、ceph-deploy.tar.gz,并上传到集群的各个节点上来进行安装
2. INSTALL SOFTWARE
在我们下载好前面这些安装包之后,分别上传到集群各节点进行安装。
2.1 INSTALL CEPH DEPLOY
这里我们虽然是通过手动方式来安装ceph集群,但是我们还是可以安装ceph-deploy来让其协助我们完成手动安装。
在ceph001-admin节点上安装ceph-deploy包:
sudo rpm –ivh ceph-deploy-1.5.37-0.noarch.rpm
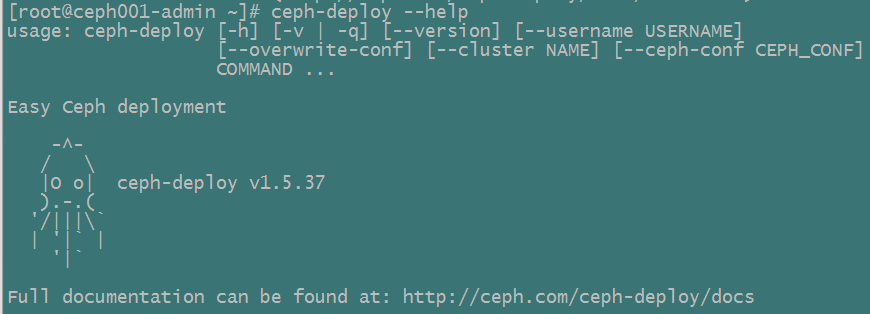
执行ceph-deploy看是否安装成功:
2.3 INSTALL CEPH STORAGE CLUSTER
本手册描述了如何手动的安装ceph包。如下的安装过程只适应于那些没有安装ceph-deploy、juju等工具的用户。
INSTALL WITH RPM
通过RPM包来安装CEPH,请执行如下的步骤:
1) 安装pre-requisite 包 在所有节点上安装如下包:
- snappy
- leveldb
- gdisk
- python-argparse
- gperftools-libs

执行如下命令进行安装:
sudo yum localinstall *.rpm
2) 在所有节点上安装ceph包

执行如下命令进行安装:
sudo yum localinstall *.rpm
2.4 MANUAL DEPLOYMENT
一个Ceph Cluster至少需要一个monitor,和尽可能多的OSDs来存放对象数据的副本。建立initial monitors是构建Ceph Storage Cluster的首要步骤。Monitor的部署会为整个集群建立重要的准则,比如pools的副本数,每一个OSD的placement groups数,heartbeat间隔,是否需要身份认证等。这些值的大多数都会被设置为默认值,因此在实际产品应用中构建集群的时候我们需要了解到这些。
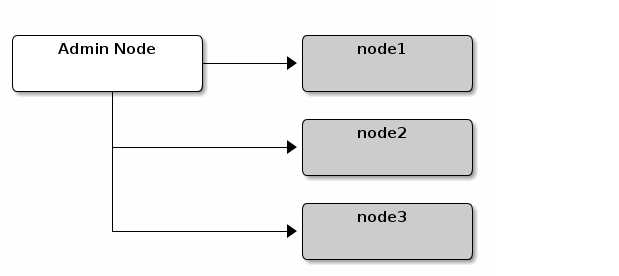
我们参照如下图来构建集群,node1作为monitor node,node2与node3作为OSD nodes。
1) MONITOR BOOTSTRAPPING
构建一个monitor需要如下一些步骤:
Unique Identifier:fsid是集群的唯一标识符,且代表着Ceph Storage Cluster所对应的Ceph Filesystem的文件系统ID。当前,ceph已经支持native interface,block device,object storage gateway interface,因此从这一方面来说fsid已经有些不恰当了。Cluster Name:ceph clusters拥有一个cluster名称 ,它是一个不带空格的简单字符串。默认的集群名称为ceph。当你有多个集群的时候,为了清楚的区分当前的集群,修改默认的集群名称就显得很有意义了
例如,当你在一个federated architecture环境中运行多个ceph集群的时候,集群的名字(eg: us-west, us-east)标识着当前是哪一个集群的回话。 NOTE:为了在命令行接口区别cluster name,可以通过集群名字来命名ceph configuration(eg, ceph.conf,us-west.conf, us-east.conf等)。请参看:CLI usage (ceph –cluster {cluster-name})
-
Monitor Name:集群中的每一个monitor实例都有一个唯一的名字。通常情况下,ceph-monitor的名字会被设为主机的名字(我们建议一个host上只有一个Monitor,并且不会Ceph OSD Daemons与Ceph monitor混在一起)。你可以通过hostname –s来获得当前主机的名字 Monitor Map:建立initial monitor(s)通常需要建立一个monitor map。Monitor map需要fsid,cluster name(或者使用默认的ceph),和至少一个主机名与它的IP地址Monitor Keyring:monitor相互之间的通信是通过一个secret key来完成的。你必须通过一个monitor secret来产生一个keyring以供建立initial monitor使用Administrator Keyring:要使用ceph CLI工具,你必须要有一个client.admin用户,因此你必须要产生一个admin user和keyring,然后你必须添加client.admin 用户到monitor keyring中
上面提到的这么一些需求并不意味着需要创建一个Ceph配置文件。然而,通常情况下,我们建议创建一个ceph配置文件,然后里面配有fsid,mon initial members,和mon host等
你也可以在运行过程中获得和设置monitor settings。然而,一个ceph配置文件只需要包含那些需要覆盖默认值的设置。当你添加设置到Ceph配置文件中的时候,这些设置会覆盖系统的默认值。在一个配置文件中维持这些默认值有助于方面的管理整个集群。
整个建立步骤如下:
1.1)登录initial monitors节点
ssh {hostname}
1.2)确保你有一个目录来存放ceph配置文件。默认情况下,ceph会使用/etc/ceph。当你安装ceph的时候,安装程序也会为你自动的创建/etc/ceph目录
ls /etc/ceph
NOTE: 当你purging一个集群的时候,Deployment tools会删除该目录(例如: ceph-deploy purgedata {node-name}, ceph-deploy purge {node-name})
1.3)创建一个ceph配置文件。默认情况下,Ceph会使用ceph.conf,这里ceph反应了集群的名字
sudo vim /etc/ceph/ceph.conf
1.4)为集群产生一个唯一的ID(ie.. fsid)
uuidgen
1.5)添加唯一的ID到ceph配置文件中
fsid = {UUID}
例如:
fsid = 405c269b-cb07-434f-9a78-e0d845678030
1.6)添加initial monitors到ceph配置文件中
mon initial members = {hostname}[,{hostname}]
例如:
mon initial members = ceph001-node1
1.7)添加initial monitors的IP地址到ceph配置文件中,然后保存文件
mon host = {ip-address}[,{ip-address}]
例如:
mon host = 10.133.134.211
NOTE:你也可以添加IPv6地址来代替IPv4地址,但是你必须设置ms bind ipv6为true。请参看网络配置章节:http://docs.ceph.com/docs/master/rados/configuration/network-config-ref
1.8)为集群创建一个keyring并且产生一个monitor secret key
ceph-authtool --create-keyring /tmp/ceph.mon.keyring --gen-key -n mon. --cap mon 'allow *'
1.9)产生一个administrator keyring,产生一个client.admin用户并将该用户添加到keyring中
sudo ceph-authtool --create-keyring /etc/ceph/ceph.client.admin.keyring --gen-key -n client.admin --set-uid=0 --cap mon 'allow *' --cap osd 'allow *' --cap mds 'allow'
1.10)添加client.admin key到ceph.mon.keyring中
ceph-authtool /tmp/ceph.mon.keyring --import-keyring /etc/ceph/ceph.client.admin.keyring
1.11)使用hostname(s),host IP address(es)与fsid产生一个monitor map,并将其保存为/tmp/normap
monmaptool --create --add {hostname} {ip-address} --fsid {uuid} /tmp/monmap
例如:
monmaptool --create --add ceph001-node1 10.133.134.211 --fsid 405c269b-cb07-434f-9a78-e0d845678030 /tmp/monmap
1.12)在monitor host(s)上创建一个默认的数据目录
sudo mkdir /var/lib/ceph/mon/{cluster-name}-{hostname}
例如:
sudo mkdir /var/lib/ceph/mon/ceph-ceph001-node1
请参看:monitor config reference –data来了解详细信息 (http://docs.ceph.com/docs/master/rados/configuration/mon-config-ref#data)
1.13)Populate the monitor daemon(s) with the monitor map and keyring
sudo -u ceph ceph-mon [--cluster {cluster-name}] --mkfs -i {hostname} --monmap /tmp/monmap --keyring /tmp/ceph.mon.keyring
例如:
sudo ceph-mon --mkfs -i ceph001-node1 --monmap /tmp/monmap --keyring /tmp/ceph.mon.keyring
注意:这里我们还不能以ceph身份创建
1.14)考虑ceph配置文件的设置,通常情况下包含如下一些设置:
[global]
fsid = {cluster-id}
mon initial members = {hostname}[, {hostname}]
mon host = {ip-address}[, {ip-address}]
public network = {network}[, {network}]
cluster network = {network}[, {network}]
auth cluster required = cephx
auth service required = cephx
auth client required = cephx
osd journal size = {n}
osd pool default size = {n} # Write an object n times.
osd pool default min size = {n} # Allow writing n copy in a degraded state.
osd pool default pg num = {n}
osd pool default pgp num = {n}
osd crush chooseleaf type = {n}
在我们前面的例子中,[global]段的配置类似于:
[global] fsid = 405c269b-cb07-434f-9a78-e0d845678030 mon initial members = ceph001-node1 mon host = 10.133.134.211 public network = 10.133.134.0/24 auth cluster required = cephx auth service required = cephx auth client required = cephx osd journal size = 1024 osd pool default size = 2 osd pool default min size = 1 osd pool default pg num = 333 osd pool default pgp num = 333 osd crush chooseleaf type = 1
此外,这里还需要添加针对当前节点monitor的配置:
[mon.ceph001-node1] host = ceph001-node
上面我们只需要添加host字段,其他的均采用默认配置mon_data, mon_addr均为默认值。
mon_data的默认值为/var/lib/ceph/mon/${cluster-name}-${node-name}
mon_addr的默认值为:${node-ip}:6789,主要是用于monitor之间的通信
1.15)建立done文件
标志monitor已经建立起来了,并且可以开始启动工作
sudo touch /var/lib/ceph/mon/ceph-ceph001-node1/done
1.16)启动monitors
针对Debian/CentOS/RHEL,通过如下的方式启动:
sudo /etc/init.d/ceph start mon.ceph001-node1
有些环境下可能没有/etc/init.d/ceph,这时可以直接通过如下启动:
ceph-mon --id=ceph001-node1
1.17)验证ceph已经创建了默认的pools
ceph osd lspools
你会看到类似于如下的信息:
0 data,1 metadata,2 rbd,
1.18)验证monitor已经正在运行
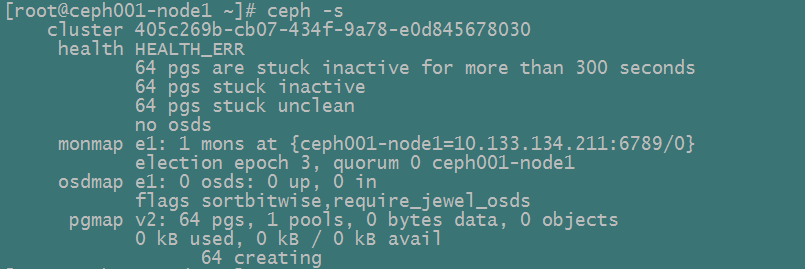
ceph -s
你会看到类似于如下的信息输出,health error 指示着placement groups处于stuck inactive状态:
NOTE:一旦你添加了OSDs并启动,placement group health errors就会消失
2) MANAGER DAEMON CONFIGURATION
在你部署ceph-mon daemon的每一个节点上,你都应该建立一个ceph-mgr daemon。
请参看:mgr/administrator
http://docs.ceph.com/docs/master/install/manual-deployment/#id1

3) ADDING OSDs
一旦你已经建立并成功运行了initial monitor(s),你应该添加一些OSDs。 在你未添加到足够的OSDs来存储对象数据的副本之前,整个集群将不能达到active + clean状态(例如:osd pool default size = 2,表明至少需要2个OSDs)。在一步一步建立起monitor之后, 你的集群就有一个默认的CRUSH map;然而,该CRUSH map并没有映射到Ceph Node的Ceph OSD Daemons。
SHORT FORM
Ceph 提供了一个ceph-disk的工具,可以用来初始化一块硬盘,进行分区等。ceph-disk工具通过增加索引的方式来创建OSD ID。另外,ceph-disk会为你添加这个新的OSD到CRUSH map中。ceph-disk工具是如下的Long Form的一个简化。我们可以用short form的流程来创建两个OSDs,请在ceph001-node2与ceph002-node3上执行如下命令:
3.1.1)Prepare the OSD
ssh {node-name}
sudo ceph-disk prepare --cluster {cluster-name} --cluster-uuid {uuid} --fs-type {ext4|xfs|btrfs} {data-path} [{journal-path}]
这里我们配置为:
ssh ceph001-node2
sudo ceph-disk prepare --cluster ceph --cluster-uuid 405c269b-cb07-434f-9a78-e0d845678030 --fs-type ext4 /dev/hdd1
3.1.2)Activate the OSD
sudo ceph-disk activate {data-path} [--activate-key {path}]
例如:
sudo ceph-disk activate /dev/hdd1
NOTE:假如在部署的Ceph节点上没有/var/lib/ceph/bootstrap-osd/{cluster}.keying文件,请使用--activate-key参数来指定。
LONG FORM
在不使用任何其他辅助工具的情况下,我们来创建一个OSD并且将它添加到集群中,然后将该OSD节点添加到CRUSH map中。我们可以用long form 的流程来创建两个OSDs,请在ceph001-node2与ceph001-node3上执行如下命令:
3.2.1) 连接登录上OSD主机
ssh {node-name}
3.2.2) 为OSD产生一个UUID
uuidgen
3.2.3) 创建OSD。假若UUID未指定,它将会在OSD启动的时候自动的被设置,如下的命令会输出OSD number,你需要在如下的步骤用使用到该值
ceph osd create [{uuid} [{id}]]
注意,这里需要将上面安装monitors时候产生的ceph.conf及ceph.client.admin.keyring拷贝到ceph001-node2、ceph001-node3的/etc/ceph目录下
3.2.4)为你新创建的OSD创建默认的目录
ssh {new-osd-host}
sudo mkdir /var/lib/ceph/osd/{cluster-name}-{osd-number}
3.2.5)假如不是直接通过操作系统来挂载一块硬盘的话,这里在建立OSD的时候必须将硬盘挂载到上面你所创建的目录下
ssh {new-osd-host}
sudo mkfs -t {fstype} /dev/{hdd}
sudo mount -o user_xattr /dev/{hdd} /var/lib/ceph/osd/{cluster-name}-{osd-number}
3.2.6)初始化OSD数据目录
ssh {new-osd-host}
sudo ceph-osd -i {osd-num} --mkfs --mkkey --osd-uuid [{uuid}]
在你运行带有–mkkey选项的ceph-osd之前,必须要保证所初始化的OSD数据目录为空。另外,ceph-osd工具可以通–cluster选项来指定集群的名称(如何是自定义的集群名称,需要通过此选项来指定)。
3.2.7)注册OSD身份验证的key
sudo ceph auth add osd.{osd-num} osd 'allow *' mon 'allow profile osd' -i /var/lib/ceph/osd/{cluster-name}-{osd-num}/keyring
3.2.8)将Ceph节点添加到CRUSH map中
ceph [--cluster {cluster-name}] osd crush add-bucket {hostname} host
例如:
ceph osd crush add-bucket ceph001-node2 host
3.2.9)将该Ceph Node放到root default下
ceph osd crush move ceph001-node2 root=default
3.2.10)将该OSD添加到CRUSH map中使其可以开始接收数据
ceph [--cluster {cluster-name}] osd crush add {id-or-name} {weight} [{bucket-type}={bucket-name} ...]
例如:
ceph osd crush add osd.0 1.0 host=ceph001-node2
3.2.11)在ceph.conf中添加当前OSD节点的配置
[osd.{osd-num}]
host = {hostname}
osd_data = {hostdata directory}
osd_journal_size = {osd journal size} #单位MB
osd_journal = {journal directory}
一般情况下,host字段必须要进行设置。其他字段根据需要进行设置或直接采用默认值。
3.2.12)在你添加了一个OSD到Ceph集群中后,该OSD就处于你集群的配置当中了。然而,它名没有真正开始运行。该OSD仍然处于down和in状态,在你开始接收数据之前你必须将其启动
针对Debian/CentOS/RHEL,使用sysvinit来启动:
sudo /etc/init.d/ceph start osd.{osd-num} [--cluster {cluster-name}]
例如:
sudo /etc/init.d/ceph start osd.0 sudo /etc/init.d/ceph start osd.1
(在某些情况下,直接使用ceph-osd --id=${osd-num}来启动)
在这种情况下,为了使每一次系统重启的时候都能够自动的启动daemon,你必须创建一个类似与如下的文件:
sudo touch /var/lib/ceph/osd/{cluster-name}-{osd-num}/sysvinit
例如:
sudo touch /var/lib/ceph/osd/ceph-0/sysvinit sudo touch /var/lib/ceph/osd/ceph-1/sysvinit
一旦你成功的启动了OSD,OSD的状态就会变成up和in状态。
4) ADDING MDS
在如下的指令中,{id}是一个随机的名字,比如机器的主机名。(我们在ceph001-node1主机上部署mds)
4.1)创建一个mds数据目录
mkdir -p /var/lib/ceph/mds/{cluster-name}-{id}
这里配置为:
mkdir -p /var/lib/ceph/mds/ceph-ceph001-node1
4.2)创建一个keyring
ceph-authtool --create-keyring /var/lib/ceph/mds/{cluster-name}-{id}/keyring --gen-key -n mds.{id}
这里配置为:
ceph-authtool --create-keyring /var/lib/ceph/mds/ceph-ceph001-node1/keyring --gen-key -n mds.ceph001-node1
4.3)导入keyring并且设置一些权限
ceph auth add mds.{id} osd "allow rwx" mds "allow" mon "allow profile mds" -i /var/lib/ceph/mds/{cluster}-{id}/keyring
这里配置为:
ceph auth add mds.ceph001-node1 osd "allow rwx" mds "allow" mon "allow profile mds" -i /var/lib/ceph/mds/ceph-ceph001-node1/keyring
4.4)添加到ceph.conf中
[mds.{id}]
host = {id}
这里配置为:
[mds.ceph001-node1] host = ceph001-node1
4.5)手动的启动ceph-mds
ceph-mds --cluster {cluster-name} -i {id} -m {mon-hostname}:{mon-port} [-f]
这里配置为:
ceph-mds --cluster ceph -i ceph001-node1 -m ceph001-node1:6789
4.6)通过service方式启动mds
service ceph start
4.7)假若启动mds守护进程的时候遇到如下错误
mds.-1.0 ERROR: failed to authenticate: (22) Invalid argument
遇到这种情况,你需要确保在ceph.conf文件的[global]段并没有设置keyring。将keyring添加到client段,或者为ceph-mds特别指定一个keyring。然后确保mds 数据目录中的keyring与ceph auth get mds.{id}输出的keyring一致。
4.8) 下面你就可以准备创建一个文件系统了
参看:http://docs.ceph.com/docs/master/cephfs/createfs
5)SUMMARY
一旦你建立了一个monitor,然后还有两个OSDs在运行,你就可以通过如下的命令监视placement groups peer。
ceph -w
以树形方式查看:
ceph osd tree
